Using Tally Table to Remove Invalid XML Characters
A couple of weeks ago, I was called in to troubleshoot an error occurring in a SQL stored procedure. The procedure was selecting a variety of information out as XML data. The error occurred because on of the columns being included was a text data column, which included raw text notes brought in to the system from a variety of sources. Some of these sources included characters that are invalid in XML.
Thinking this was a common issue, I went to google. I found the common solution was something like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
DECLARE @IncorrectCharLoc SMALLINT, --Position of bad character <pre class="lang:tsql decode:true " >DECLARE @IncorrectCharLoc SMALLINT, --Position of bad character @Pattern CHAR(37) --Bad characters to look for SELECT @Pattern = '%[' + CHAR(0)+CHAR(1)+CHAR(2)+CHAR(3)+CHAR(4) + CHAR(5)+CHAR(6)+CHAR(7)+CHAR(8)+CHAR(9) + CHAR(10)+CHAR(11)+CHAR(12)+CHAR(13)+CHAR(14) + CHAR(15)+CHAR(16)+CHAR(17)+CHAR(18)+CHAR(19) + CHAR(20)+CHAR(21)+CHAR(22)+CHAR(23)+CHAR(24) + CHAR(25)+CHAR(26)+CHAR(27)+CHAR(28)+CHAR(29) + CHAR(30)+CHAR(31)+CHAR(127) + ']%', @IncorrectCharLoc = PATINDEX(@Pattern, @TestString) WHILE @IncorrectCharLoc > 0 BEGIN SELECT @TestString = STUFF(@TestString, @IncorrectCharLoc, 1, ''), @IncorrectCharLoc = PATINDEX(@Pattern, @TestString) END SELECT @TestString |
This code is fine. It works well, and I like using the PATINDEX function to evaluate a string of characters against a REGEX expression. (I have a newly discovered appreciation for REGEX. I should post more about that…)
How Do We Improve This?
One thing sat poorly with me about this solution, though. I don’t like the WHILE loop.
Transact-SQL is built to work on big sets of data all at once. When you use a WHILE loop, you’re forcing the database to work on one piece of information at a time.
Over the last several years, I’ve convinced myself that any data manipulation that your programmer brain wants to do with a WHILE loop can be done more quickly using a Tally table. If you aren’t using Tally tables regularly, go ahead and read from this link. No single article has improved my skill set more than this.
So, I wrote an equivalent function to remove my XML characters.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
DECLARE @Pattern CHAR(37) --Bad characters to look for SELECT @Pattern = '%[' + CHAR(0)+CHAR(1)+CHAR(2)+CHAR(3)+CHAR(4) + CHAR(5)+CHAR(6)+CHAR(7)+CHAR(8)+CHAR(9) + CHAR(10)+CHAR(11)+CHAR(12)+CHAR(13)+CHAR(14) + CHAR(15)+CHAR(16)+CHAR(17)+CHAR(18)+CHAR(19) + CHAR(20)+CHAR(21)+CHAR(22)+CHAR(23)+CHAR(24) + CHAR(25)+CHAR(26)+CHAR(27)+CHAR(28)+CHAR(29) + CHAR(30)+CHAR(31)+CHAR(127) + ']%' ;WITH t1 AS (SELECT 1 N UNION ALL SELECT 1 N), t2 AS (SELECT 1 N FROM t1 x, t1 y), t3 AS (SELECT 1 N FROM t2 x, t2 y), t4 AS (SELECT 1 N FROM t3 x, t3 y), t5 AS (SELECT 1 N FROM t4 x, t4 y), cteTally AS (SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) N FROM t5 x, t5 y) , -- cte to return each character on a seperate row. 1st where condition eliminates the -- unwanted characters cteEachChar AS ( SELECT N , SUBSTRING(@TestString, N, 1) AS Ch FROM cteTally WHERE PATINDEX(@Pattern, SUBSTRING(@TestString, N, 1)) = 0 AND N <= LEN(@TestString) ), -- cte puts the characters back into a single row/single column cteStringify(NewString) AS ( SELECT Ch [text()] FROM cteEachChar FOR XML PATH('') ) -- fix our spaces (FOR XML added coding) SELECT REPLACE(NewString, ' ', ' ') FROM cteStringify |
What Are We Doing, Exactly?
The Common Table Expressions t1, t2, t3, t4, t5, and cteTally just build a Tally table — a result set that spits out numbers in order. In this case, I’ve cross-joined enough rows to return numbers from 1 to 4,294,967,296 which is ridiculous overkill.
The CTE named cteEachChar splits our text into a list of individual characters.
|
1 2 3 4 5 6 7 |
cteEachChar AS ( SELECT N , SUBSTRING(@TestString, N, 1) AS Ch FROM cteTally WHERE PATINDEX(@Pattern, SUBSTRING(@TestString, N, 1)) = 0 AND N <= LEN(@TestString) ) |
In this subquery, N is the column representing the number from cteTally. The column returned as Ch, then, is the Nth character of our test string. You end up with one character on each row if you select directly out of this CTE.
The WHERE clause uses the LEN function so that there’s no need for the server to evaluate rows up to 4,294,967,296. I would think it helps performance when there’s a short string, but I didn’t test it to see for sure. The more important term in the WHERE clause is our same PATINDEX, which removes those rows where the characters are invalid for XML. Mission complete!
Well, almost complete. We still have to merge our single-character rows back into one big line of characters.
|
1 2 3 4 5 |
cteStringify(NewString) AS ( SELECT Ch [text()] FROM cteEachChar FOR XML PATH('') ) |
That brings us to our last CTE. Here, we use a trick for combining information from different rows into a single result using the FOR XML construct.
I wish I knew who to whom to credit this construct. I’ve been using it for a long time to combine different rows’ information into a delimited list. (SELECT ‘, ‘ + Ch [text()]), then use SUBSTRING to get rid of the first comma and space.
My original function puts it all back together again, but without my delimiter, it changes my spaces to “ ”. The final select replaces those with the actual space that I want.
No real reason that I specified the column name next to the name of the CTE in this case rather than in the select statement itself. I normally like having column names in the SELECT, because I find that a little easier to read. But I can be flexible with it. 🙃
|
1 2 |
SELECT REPLACE(NewString, '&#x20;', ' ') FROM cteStringify |
How Does This Really Perform?
In the data set where I hit this problem, the old script and my new made no discernible performance difference. They were both more or less instant. But if I bundle this up as a function, someone somewhere is going to apply it to millions of rows, each potentially having millions of characters of data. So let’s test with something big.
I created a test string, made up of the sentence, “The quick brown fox jumped over the lazy dogs.” I dropped 800 invalid XML characters into the middle of this, and then replicated that big character string a million times. Then, I added a variable for start time, and a DATEDIFF function at the end so we can see how long it took to run. Here are the final queries and results from my underpowered development machine.
(As with all SQL performance tests, much of this is dependent on hardware and on what else our servers are doing, so we can compare two results, but anyone’s specific result on a specific machine may vary widely.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
DECLARE @TestString VARCHAR(MAX), @StartTime datetime2 SELECT @TestString = REPLICATE('The quick brown fox' + REPLICATE(CHAR(16), 800) + ' jumped over the lazy dogs. ',1000000) , @StartTime = GETDATE() DECLARE @IncorrectCharLoc SMALLINT, --Position of bad character @Pattern CHAR(37) --Bad characters to look for SELECT @Pattern = '%[' + CHAR(0)+CHAR(1)+CHAR(2)+CHAR(3)+CHAR(4) + CHAR(5)+CHAR(6)+CHAR(7)+CHAR(8)+CHAR(9) + CHAR(10)+CHAR(11)+CHAR(12)+CHAR(13)+CHAR(14) + CHAR(15)+CHAR(16)+CHAR(17)+CHAR(18)+CHAR(19) + CHAR(20)+CHAR(21)+CHAR(22)+CHAR(23)+CHAR(24) + CHAR(25)+CHAR(26)+CHAR(27)+CHAR(28)+CHAR(29) + CHAR(30)+CHAR(31)+CHAR(127) + ']%', @IncorrectCharLoc = PATINDEX(@Pattern, @TestString) WHILE @IncorrectCharLoc > 0 BEGIN SELECT @TestString = STUFF(@TestString, @IncorrectCharLoc, 1, ''), @IncorrectCharLoc = PATINDEX(@Pattern, @TestString) END SELECT @TestString AS CorrectedText SELECT @StartTime AS StartTime, GETDATE() AS EndTime, DATEDIFF(ms, @StartTime, GETDATE()) AS NumMilliseconds |
The results on my underpowered development box:
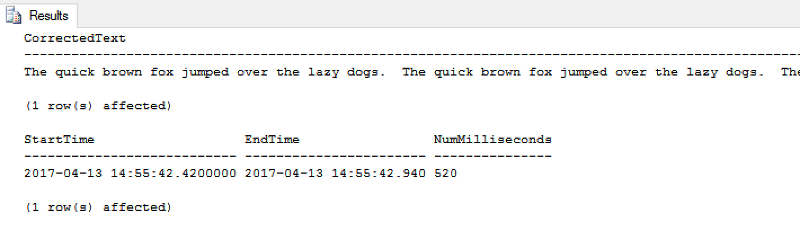
Now, the full query and the results on the same test data using the Tally Table method:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
DECLARE @TestString VARCHAR(MAX), @StartTime datetime2 SELECT @TestString = REPLICATE('The quick brown fox' + REPLICATE(CHAR(16), 800) + ' jumped over the lazy dogs. ',1000000) , @StartTime = GETDATE() DECLARE @IncorrectCharLoc SMALLINT, --Position of bad character @Pattern CHAR(37) --Bad characters to look for SELECT @Pattern = '%[' + CHAR(0)+CHAR(1)+CHAR(2)+CHAR(3)+CHAR(4) + CHAR(5)+CHAR(6)+CHAR(7)+CHAR(8)+CHAR(9) + CHAR(10)+CHAR(11)+CHAR(12)+CHAR(13)+CHAR(14) + CHAR(15)+CHAR(16)+CHAR(17)+CHAR(18)+CHAR(19) + CHAR(20)+CHAR(21)+CHAR(22)+CHAR(23)+CHAR(24) + CHAR(25)+CHAR(26)+CHAR(27)+CHAR(28)+CHAR(29) + CHAR(30)+CHAR(31)+CHAR(127) + ']%', @IncorrectCharLoc = PATINDEX(@Pattern, @TestString) WHILE @IncorrectCharLoc > 0 BEGIN SELECT @TestString = STUFF(@TestString, @IncorrectCharLoc, 1, ''), @IncorrectCharLoc = PATINDEX(@Pattern, @TestString) END SELECT @TestString AS CorrectedText SELECT @StartTime AS StartTime, GETDATE() AS EndTime, DATEDIFF(ms, @StartTime, GETDATE()) AS NumMilliseconds |
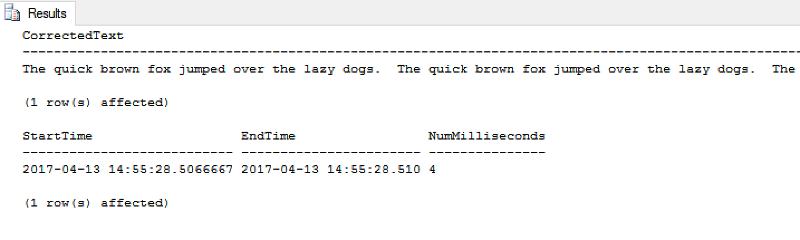
Repeated tests showed execution times in the same general area.
It seems like a lot of work to knock out 500 milliseconds, but I look at it as reducing the time by two orders of magnitude. Perhaps someday, this method reduces someone’s job from running into 100 hours down to running in one hour.